



こんにちは、グラフィックデザイナーのyoen(@yoen)です。
今回はAcrobatで使えるOCRのご紹介です。
OCRとはフォント情報を持たない文字をテキストにする機能のことです。
OCRは、Optical Character Reader(またはRecognition)の略で、画像データのテキスト部分を認識し、文字データに変換する光学文字認識機能のことを言います。具体的にいうと、紙文書をスキャナーで読み込み、書かれている文字を認識してデジタル化する技術です。
RICOH
昔は手書き文字や紙の文章をスキャナーで読み込み、専用ソフトでテキスト化していました。ですが精度が良いとは言えず仕事で使えるレベルではありませんでした。
しかし今ではAcrobatやGoogleが提供している機能でかなりの精度で読み取ってくれるありがたい機能になっていますのでご紹介したいと思います。
今回はより実践的にということで支給されたPDFドキュメントのアウトラインがかかったデータからテキスト化する工程を見てみたいと思います。
OCR機能は環境やデータによって大きく効果が変わってしまうことが多いです。今回のテストではうまくいっていますが単純なものでもうまく機能しない場合があるのでそれを踏まえてご覧いただけると助かります。
それでは見ていきましょう。
今のOCRはすごいぞ!【Acrobat】
今回はこのデータで見ていきたいと思います。
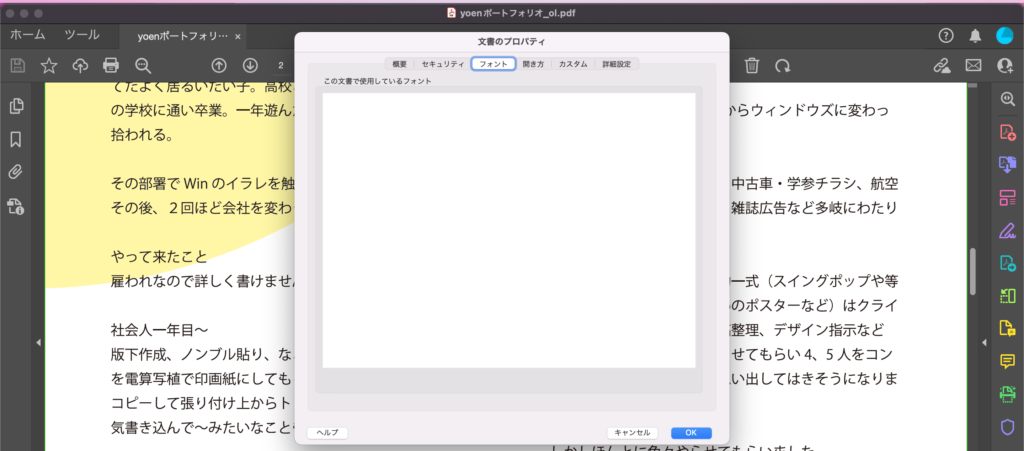
Acrobatのプロパティで確認してみるとフォント情報がありません。こちらを使ってテキスト化してみたいと思います。
スキャンとOCR
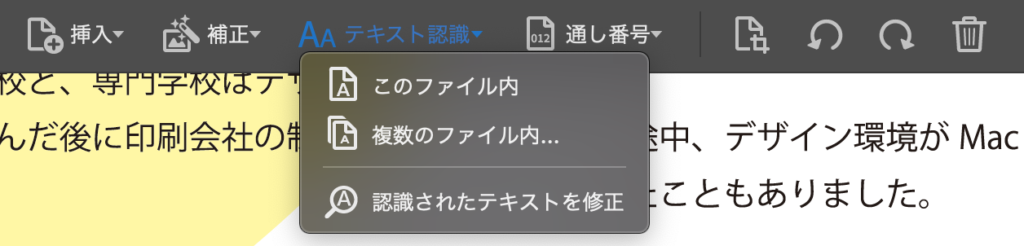
まずはスキャンとOCRを開きます。右側のツール群の中にない場合は、ツール→作成と編集→スキャンとOCRを選びましょう。

上部にツールが表示されます。
左から挿入:ファイルを開いたりスキャナーがある場合はここから選択します。
補正:スキャンしたデータが荒かったりした場合ここで画像の補正が出来ます。
テキスト認識:ここで実際にテキスト化していきます。
通し番号:割愛します。

それではテキスト認識をクリックしてみましょう。テキスト化する範囲を設定できます。ここではこのファイル内を選択しました。
すると、もう一段下にツールが出てきます。言語などを設定しテキスト認識を選択しましょう。

処理が終わったらツール ![]() 文字と画像の選択ツールで確認してみましょう。
文字と画像の選択ツールで確認してみましょう。
テキストとして復活することが出来ました。

今回は以下のような場所でテキスト化することが出来ませんでした。やはりグラフィカルに処理している部分は難しいようですね。

初めにも書きましたが今回のテストではうまくいっていますが単純なものでもうまく機能しない場合があるのでそれを踏まえてテキスト化出来たらラッキー程度に捉えておきましょう。
まとめ
いかがでしたでしょうか。
手書き文字でも綺麗に画像化できていればテキストとして読み込むことができるのでぜひチャレンジしてみてください。
この他にもGoogleドキュメントでも読み込めたりするので後日改めて紹介したいと思っています。
これからもデザイナーにとって有益な情報を発信していこうと思いますのでぜひよろしくお願いいたします。
それでは、よきデザインライフを。
デザインやAdobeに興味がある方は、AmazonのAdobeサイトでのご購入がお勧めです。
ちょくちょくセールもやっているのでたまに見に行ってみてね。
よきデザインライフを!


コメント